
Deep finding out is now being utilised to translate concerning languages, forecast how proteins fold, review clinical scans, and participate in online games as complicated as Go, to name just a couple of purposes of a procedure that is now getting to be pervasive. Results in those and other realms has introduced this equipment-finding out procedure from obscurity in the early 2000s to dominance today.
Despite the fact that deep learning’s increase to fame is somewhat modern, its origins are not. In 1958, back again when mainframe personal computers filled rooms and ran on vacuum tubes, understanding of the interconnections concerning neurons in the mind influenced
Frank Rosenblatt at Cornell to structure the first artificial neural network, which he presciently explained as a “pattern-recognizing device.” But Rosenblatt’s ambitions outpaced the capabilities of his era—and he knew it. Even his inaugural paper was compelled to accept the voracious hunger of neural networks for computational energy, bemoaning that “as the quantity of connections in the network will increase…the burden on a regular digital laptop quickly turns into too much.”
The good news is for these kinds of artificial neural networks—later rechristened “deep finding out” when they involved added layers of neurons—decades of
Moore’s Legislation and other advancements in laptop hardware yielded a approximately 10-million-fold raise in the quantity of computations that a laptop could do in a second. So when researchers returned to deep finding out in the late 2000s, they wielded resources equal to the problem.
These far more-strong personal computers made it probable to build networks with vastly far more connections and neurons and that’s why increased skill to design complicated phenomena. Researchers utilised that skill to split file right after file as they utilized deep finding out to new jobs.
Whilst deep learning’s increase may well have been meteoric, its future may well be bumpy. Like Rosenblatt right before them, today’s deep-finding out researchers are nearing the frontier of what their resources can reach. To fully grasp why this will reshape equipment finding out, you should first fully grasp why deep finding out has been so successful and what it charges to hold it that way.
Deep finding out is a fashionable incarnation of the prolonged-jogging pattern in artificial intelligence that has been relocating from streamlined techniques primarily based on expert understanding toward versatile statistical types. Early AI techniques were rule primarily based, making use of logic and expert understanding to derive results. Afterwards techniques included finding out to established their adjustable parameters, but these were usually couple of in quantity.
Present day neural networks also find out parameter values, but those parameters are component of these kinds of versatile laptop types that—if they are huge enough—they turn into common perform approximators, this means they can healthy any sort of information. This endless overall flexibility is the reason why deep finding out can be utilized to so many unique domains.
The overall flexibility of neural networks comes from taking the many inputs to the design and having the network blend them in myriad ways. This means the outputs will never be the final result of making use of straightforward formulation but as an alternative immensely challenging types.
For example, when the chopping-edge picture-recognition system
Noisy College student converts the pixel values of an picture into probabilities for what the item in that picture is, it does so working with a network with 480 million parameters. The coaching to verify the values of these kinds of a large quantity of parameters is even far more exceptional because it was accomplished with only one.two million labeled images—which may well understandably confuse those of us who don’t forget from high college algebra that we are meant to have far more equations than unknowns. Breaking that rule turns out to be the crucial.
Deep-finding out types are overparameterized, which is to say they have far more parameters than there are information factors accessible for coaching. Classically, this would lead to overfitting, exactly where the design not only learns common trends but also the random vagaries of the information it was properly trained on. Deep finding out avoids this trap by initializing the parameters randomly and then iteratively modifying sets of them to better healthy the information working with a approach known as stochastic gradient descent. Incredibly, this process has been demonstrated to make certain that the acquired design generalizes nicely.
The results of versatile deep-finding out types can be noticed in equipment translation. For many years, application has been utilised to translate text from one language to an additional. Early approaches to this problem utilised regulations designed by grammar gurus. But as far more textual information turned accessible in particular languages, statistical approaches—ones that go by these kinds of esoteric names as optimum entropy, concealed Markov types, and conditional random fields—could be utilized.
Originally, the approaches that labored ideal for just about every language differed primarily based on information availability and grammatical homes. For example, rule-primarily based approaches to translating languages these kinds of as Urdu, Arabic, and Malay outperformed statistical ones—at first. Nowadays, all these approaches have been outpaced by deep finding out, which has demonstrated by itself superior almost all over the place it is really utilized.
So the great information is that deep finding out provides great overall flexibility. The undesirable information is that this overall flexibility comes at an great computational cost. This regrettable fact has two parts.
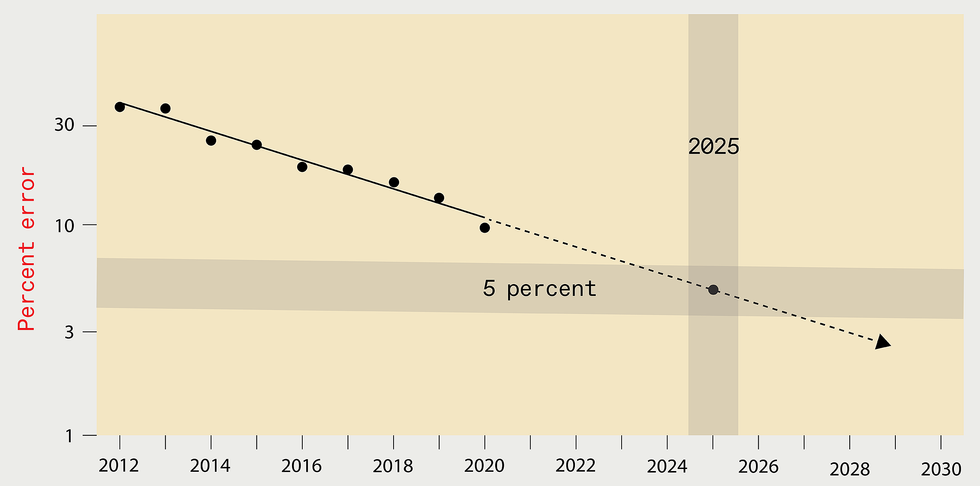
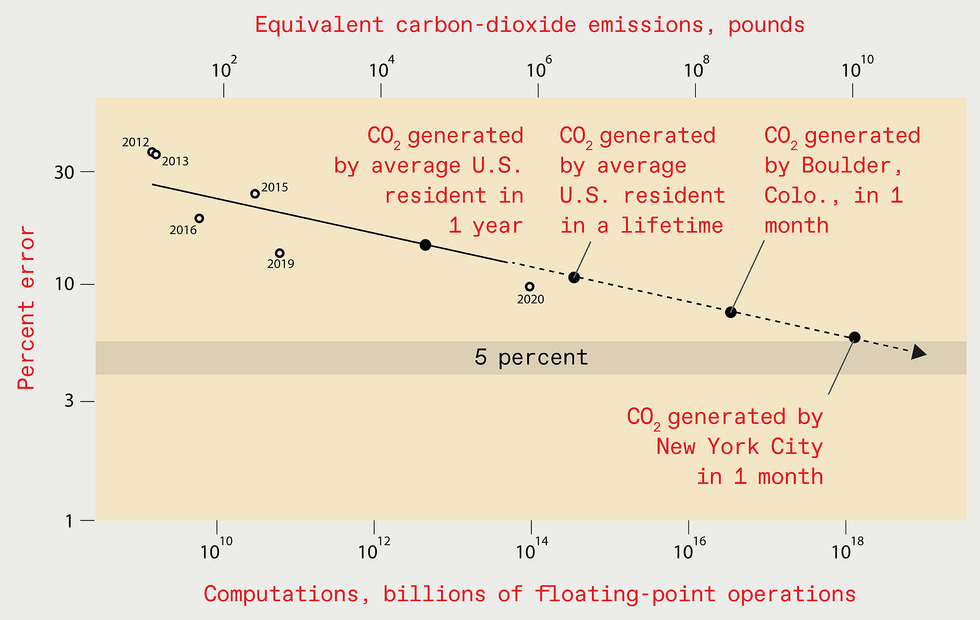
Extrapolating the gains of modern decades may well counsel that by
2025 the error amount in the ideal deep-finding out techniques designed
for recognizing objects in the ImageNet information established must be
diminished to just five % [leading]. But the computing resources and
vitality demanded to teach these kinds of a future system would be great,
major to the emission of as significantly carbon dioxide as New York
Town generates in one month [base].
Supply: N.C. THOMPSON, K. GREENEWALD, K. LEE, G.F. MANSO
The first component is legitimate of all statistical types: To improve general performance by a aspect of
k, at least ktwo far more information factors should be utilised to teach the design. The second component of the computational cost comes explicitly from overparameterization. After accounted for, this yields a full computational cost for enhancement of at least kfour. That little four in the exponent is incredibly highly-priced: A 10-fold enhancement, for example, would have to have at least a 10,000-fold raise in computation.
To make the overall flexibility-computation trade-off far more vivid, take into consideration a scenario exactly where you are trying to forecast no matter whether a patient’s X-ray reveals most cancers. Suppose further that the legitimate response can be located if you measure 100 information in the X-ray (typically known as variables or attributes). The problem is that we don’t know forward of time which variables are vital, and there could be a incredibly large pool of prospect variables to take into consideration.
The expert-system approach to this problem would be to have men and women who are experienced in radiology and oncology specify the variables they feel are vital, allowing the system to take a look at only those. The versatile-system approach is to examination as many of the variables as probable and let the system determine out on its individual which are vital, requiring far more information and incurring significantly bigger computational charges in the approach.
Types for which gurus have established the suitable variables are ready to find out speedily what values function ideal for those variables, doing so with constrained quantities of computation—which is why they were so popular early on. But their skill to find out stalls if an expert hasn’t accurately specified all the variables that must be involved in the design. In distinction, versatile types like deep finding out are significantly less productive, taking vastly far more computation to match the general performance of expert types. But, with plenty of computation (and information), versatile types can outperform types for which gurus have tried to specify the suitable variables.
Obviously, you can get enhanced general performance from deep finding out if you use far more computing energy to establish greater types and teach them with far more information. But how highly-priced will this computational burden turn into? Will charges turn into sufficiently high that they hinder progress?
To response these issues in a concrete way,
we just lately gathered information from far more than one,000 investigation papers on deep finding out, spanning the spots of picture classification, item detection, problem answering, named-entity recognition, and equipment translation. Here, we will only examine picture classification in depth, but the classes implement broadly.
Over the decades, lowering picture-classification glitches has appear with an great enlargement in computational burden. For example, in 2012
AlexNet, the design that first confirmed the energy of coaching deep-finding out techniques on graphics processing units (GPUs), was properly trained for 5 to six days working with two GPUs. By 2018, an additional design, NASNet-A, had minimize the error rate of AlexNet in half, but it utilised far more than one,000 instances as significantly computing to reach this.
Our investigation of this phenomenon also allowed us to review what is actually actually happened with theoretical expectations. Theory tells us that computing wants to scale with at least the fourth energy of the enhancement in general performance. In practice, the true necessities have scaled with at least the
ninth energy.
This ninth energy means that to halve the error rate, you can expect to want far more than five hundred instances the computational resources. That’s a devastatingly high value. There may well be a silver lining here, on the other hand. The gap concerning what is actually happened in practice and what theory predicts may well suggest that there are nonetheless undiscovered algorithmic advancements that could enormously improve the performance of deep finding out.
To halve the error rate, you can expect to want far more than five hundred instances the computational resources.
As we famous, Moore’s Legislation and other hardware improvements have furnished massive will increase in chip general performance. Does this suggest that the escalation in computing necessities would not subject? However, no. Of the one,000-fold big difference in the computing utilised by AlexNet and NASNet-A, only a six-fold enhancement came from better hardware the rest came from working with far more processors or jogging them extended, incurring bigger charges.
Acquiring estimated the computational cost-general performance curve for picture recognition, we can use it to estimate how significantly computation would be desired to arrive at even far more extraordinary general performance benchmarks in the future. For example, attaining a five % error rate would have to have 1019 billion floating-stage functions.
Critical function by students at the University of Massachusetts Amherst lets us to fully grasp the financial cost and carbon emissions implied by this computational burden. The answers are grim: Coaching these kinds of a design would cost US $100 billion and would make as significantly carbon emissions as New York Town does in a month. And if we estimate the computational burden of a one % error rate, the results are significantly worse.
Is extrapolating out so many orders of magnitude a fair matter to do? Yes and no. Surely, it is vital to fully grasp that the predictions aren’t specific, while with these kinds of eye-watering results, they don’t want to be to convey the in general message of unsustainability. Extrapolating this way
would be unreasonable if we assumed that researchers would follow this trajectory all the way to these kinds of an serious consequence. We don’t. Faced with skyrocketing charges, researchers will possibly have to appear up with far more productive ways to solve these complications, or they will abandon doing the job on these complications and progress will languish.
On the other hand, extrapolating our results is not only fair but also vital, because it conveys the magnitude of the problem forward. The major edge of this problem is previously getting to be obvious. When Google subsidiary
DeepMind properly trained its system to participate in Go, it was estimated to have cost $35 million. When DeepMind’s researchers designed a system to participate in the StarCraft II online video activity, they purposefully didn’t try out multiple ways of architecting an vital ingredient, because the coaching cost would have been far too high.
At
OpenAI, an vital equipment-finding out feel tank, researchers just lately designed and properly trained a significantly-lauded deep-finding out language system known as GPT-three at the cost of far more than $four million. Even nevertheless they made a slip-up when they applied the system, they didn’t resolve it, explaining just in a complement to their scholarly publication that “due to the cost of coaching, it wasn’t feasible to retrain the design.”
Even organizations exterior the tech business are now commencing to shy away from the computational expense of deep finding out. A large European supermarket chain just lately deserted a deep-finding out-primarily based system that markedly enhanced its skill to forecast which items would be obtained. The firm executives dropped that attempt because they judged that the cost of coaching and jogging the system would be far too high.
Faced with growing financial and environmental charges, the deep-finding out group will want to come across ways to raise general performance with no producing computing demands to go by way of the roof. If they don’t, progress will stagnate. But don’t despair nonetheless: A great deal is being accomplished to handle this problem.
A single tactic is to use processors designed particularly to be productive for deep-finding out calculations. This approach was widely utilised around the very last ten years, as CPUs gave way to GPUs and, in some circumstances, area-programmable gate arrays and application-particular ICs (together with Google’s
Tensor Processing Device). Basically, all of these approaches sacrifice the generality of the computing platform for the performance of increased specialization. But these kinds of specialization faces diminishing returns. So extended-expression gains will have to have adopting wholly unique hardware frameworks—perhaps hardware that is primarily based on analog, neuromorphic, optical, or quantum techniques. Consequently considerably, on the other hand, these wholly unique hardware frameworks have nonetheless to have significantly impression.
We should possibly adapt how we do deep finding out or deal with a future of significantly slower progress.
A different approach to lowering the computational burden focuses on making neural networks that, when applied, are lesser. This tactic lowers the cost just about every time you use them, but it typically will increase the coaching cost (what we’ve explained so considerably in this post). Which of these charges issues most depends on the predicament. For a widely utilised design, jogging charges are the major ingredient of the full sum invested. For other models—for example, those that often want to be retrained— coaching charges may well dominate. In possibly case, the full cost should be larger sized than just the coaching on its individual. So if the coaching charges are far too high, as we’ve proven, then the full charges will be, far too.
And that is the problem with the various strategies that have been utilised to make implementation lesser: They don’t lower coaching charges plenty of. For example, one lets for coaching a large network but penalizes complexity all through coaching. A different requires coaching a large network and then “prunes” away unimportant connections. Still an additional finds as productive an architecture as probable by optimizing across many models—something known as neural-architecture look for. Whilst just about every of these approaches can offer you sizeable benefits for implementation, the results on coaching are muted—certainly not plenty of to handle the concerns we see in our information. And in many circumstances they make the coaching charges bigger.
A single up-and-coming procedure that could lower coaching charges goes by the name meta-finding out. The plan is that the system learns on a assortment of information and then can be utilized in many spots. For example, alternatively than building individual techniques to realize canines in illustrations or photos, cats in illustrations or photos, and automobiles in illustrations or photos, a single system could be properly trained on all of them and utilised multiple instances.
However, modern function by
Andrei Barbu of MIT has uncovered how challenging meta-finding out can be. He and his coauthors confirmed that even modest dissimilarities concerning the initial information and exactly where you want to use it can seriously degrade general performance. They demonstrated that recent picture-recognition techniques depend closely on matters like no matter whether the item is photographed at a unique angle or in a unique pose. So even the straightforward job of recognizing the very same objects in unique poses results in the accuracy of the system to be practically halved.
Benjamin Recht of the University of California, Berkeley, and some others made this stage even far more starkly, showing that even with novel information sets purposely created to mimic the initial coaching information, general performance drops by far more than 10 %. If even modest improvements in information bring about large general performance drops, the information desired for a thorough meta-finding out system may well be great. So the great assure of meta-finding out remains considerably from being understood.
A different probable tactic to evade the computational limitations of deep finding out would be to go to other, potentially as-nonetheless-undiscovered or underappreciated kinds of equipment finding out. As we explained, equipment-finding out techniques created close to the perception of gurus can be significantly far more computationally productive, but their general performance won’t be able to arrive at the very same heights as deep-finding out techniques if those gurus are not able to distinguish all the contributing components.
Neuro-symbolic approaches and other approaches are being made to blend the energy of expert understanding and reasoning with the overall flexibility typically located in neural networks.
Like the predicament that Rosenblatt faced at the dawn of neural networks, deep finding out is today getting to be constrained by the accessible computational resources. Faced with computational scaling that would be economically and environmentally ruinous, we should possibly adapt how we do deep finding out or deal with a future of significantly slower progress. Obviously, adaptation is preferable. A clever breakthrough may well come across a way to make deep finding out far more productive or laptop hardware far more strong, which would permit us to proceed to use these extraordinarily versatile types. If not, the pendulum will very likely swing back again toward relying far more on gurus to determine what wants to be acquired.
From Your Site Posts
Related Posts All-around the Web
