
Do you want to evaluate info that resides in Google BigQuery as component of an R workflow? Thanks to the bigrquery R bundle, it is a pretty seamless encounter — as soon as you know a couple of compact tweaks required to operate dplyr features on these kinds of info.
Very first, nevertheless, you’ll have to have a Google Cloud account. Note that you’ll have to have your individual Google Cloud account even if the info is in anyone else’s account and you never plan on storing your individual info.
How to set up a Google Cloud account
Numerous folks now have common Google accounts for use with providers like Google Travel or Gmail. If you never have one particular yet, make certain to build one particular.
Then, head to the Google Cloud Console at https://console.cloud.google.com, log in with your Google account, and build a new cloud venture. R veterans notice: Although jobs are a good concept when operating in RStudio, they are mandatory in Google Cloud.
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGClick on the New Undertaking selection in order to build a new venture.
You must see the selection to build a new venture at the left aspect of Google Cloud’s prime navigation bar. Click on on the dropdown menu to the correct of “Google Cloud Platform” (it might say “select project” if you never have any jobs now). Give your venture a identify. If you have billing enabled now in your Google account you’ll be essential to find a billing account if you never, that in all probability won’t surface as an selection. Then click ”Create.”
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGIf you never like the default venture ID assigned to your venture, you can edit it in advance of clicking the Produce button.
If you never like the venture ID that is instantly generated for your venture, you can edit it, assuming you never pick anything that is now taken.
Make BigQuery less complicated to come across
The moment you finish your new venture setup, you’ll see a common Google Cloud dashboard that may perhaps feel a little bit overwhelming. What are all these things and where is BigQuery? You in all probability never have to have to stress about most of the other providers, but you do want to be able to quickly come across BigQuery in the midst of them all.
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGThe first Google Cloud residence screen can be a little bit overwhelming if you are hunting to use just one particular service. (I’ve due to the fact deleted this venture.)
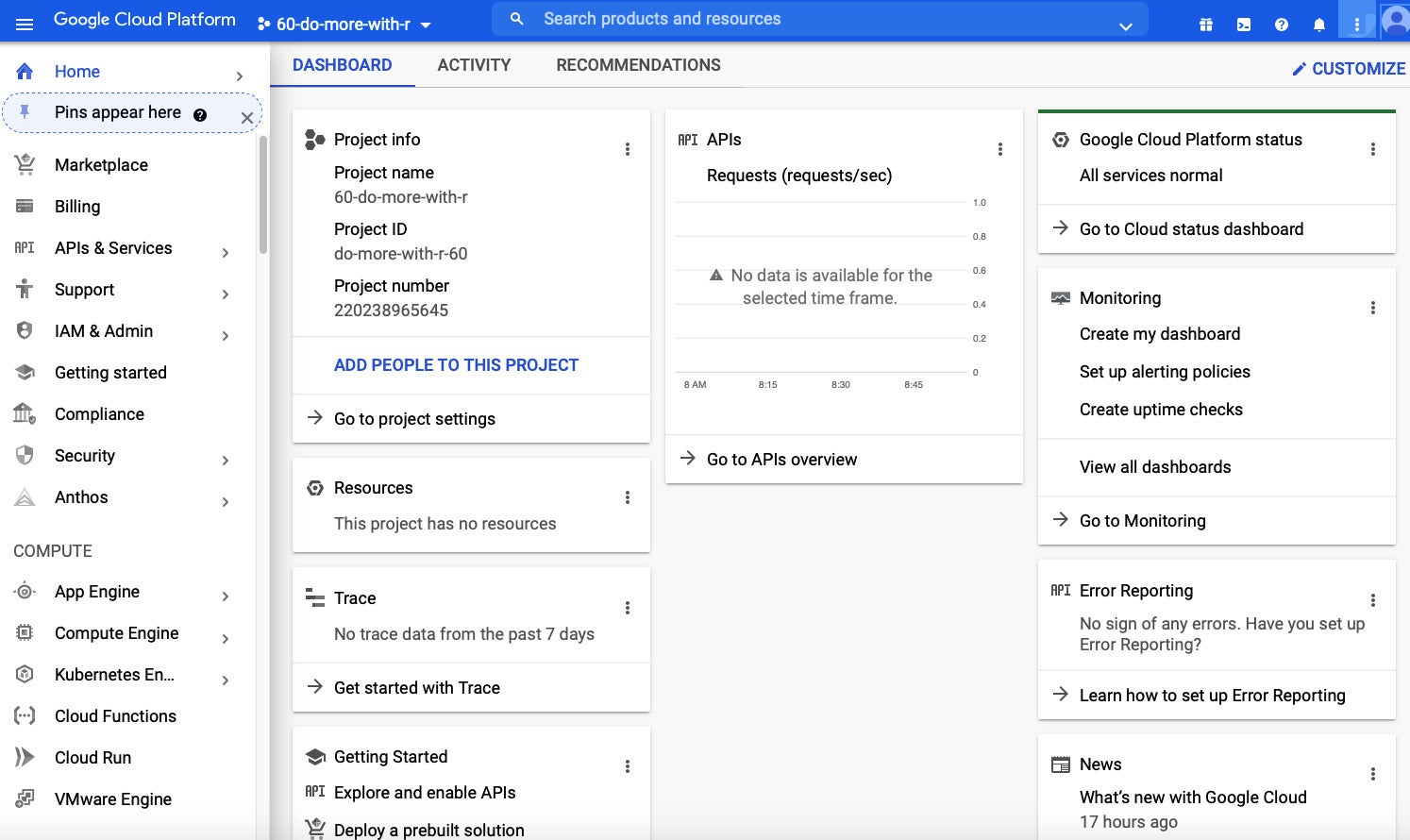
A single way is to “pin” BigQuery to the prime of your left navigation menu. (If you never see a left nav, click the three-line “hamburger” at the extremely prime left to open up it.) Scroll all of the way down, come across BigQuery, hover your mouse over it until you see a pin icon, and click the pin.
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGScroll down to the bottom of the left navigation in the main Google Cloud residence screen to come across the BigQuery service. You can “pin” it by mousing over until you see the pin icon and then clicking on it.
Now BigQuery will always exhibit up at the prime of your Google Cloud Console left navigation menu. Scroll back up and you’ll see BigQuery. Click on on it, and you’ll get to the BigQuery console with the identify of your venture and no info inside.
If the Editor tab is not straight away seen, click on the “Compose New Query” button at the prime correct.
Start off enjoying with community info
Now what? Individuals often start learning BigQuery by enjoying with an out there community info set. You can pin other users’ community info jobs to your individual venture, including a suite of info sets collected by Google. If you go to this URL in the same BigQuery browser tab you have been operating in, the Google community info venture must instantly pin by itself to your venture.
Thanks to JohannesNE on GitHub for this idea: You can pin any info set you can entry by applying the URL structure demonstrated down below.
https://console.cloud.google.com/bigquery?p=venture-id&web page=venture
If this does not function, test to make certain you’re in the correct Google account. If you have logged into a lot more than one particular Google account in a browser, you may perhaps have been despatched to a different account than you expected.
Soon after pinning a venture, click on the triangle to the left of the identify of that pinned venture (in this circumstance bigquery-community-info) and you’ll see all info sets out there in that venture. A BigQuery info set is like a typical databases: It has one particular or a lot more info tables. Click on on the triangle subsequent to a info set to see the tables it includes.
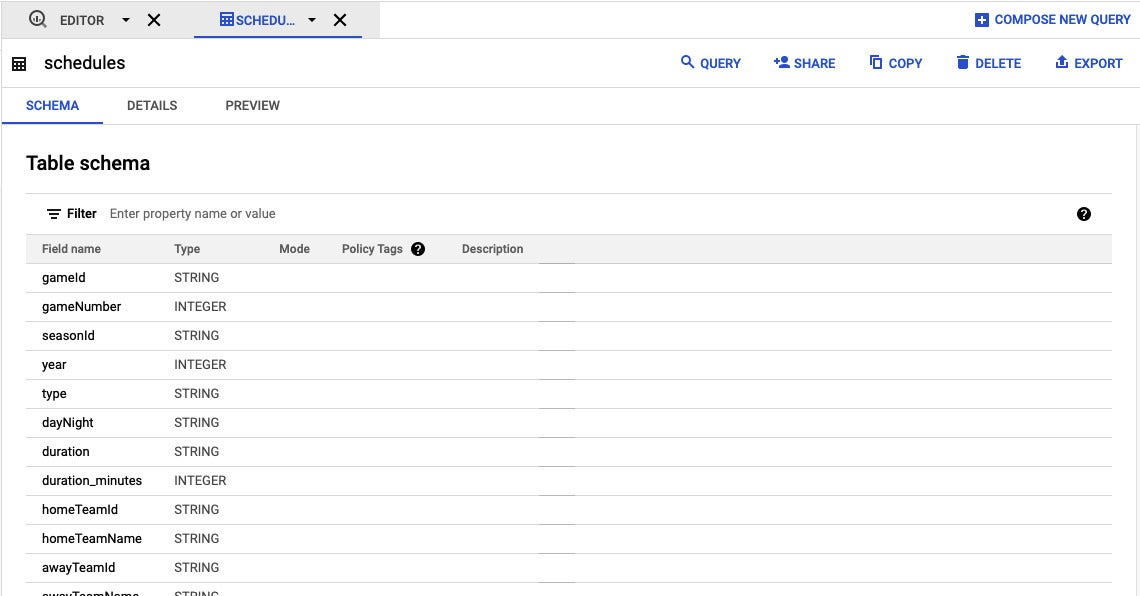 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGClicking on a table in the BigQuery website interface allows you see its schema, together with a tab for previewing info.
Click on on the table identify to see its schema. There is also a “Preview” tab that allows you watch some genuine info.
There are other, less level-and-click ways to see your info structure. But initially….
How BigQuery pricing performs
BigQuery charges for each info storage and info queries. When applying a info set developed by anyone else, they shell out for the storage. If you build and store your individual info in BigQuery, you shell out — and the charge is the same no matter whether you are the only one particular applying it, you share it with a couple other folks, or you make it community. (You get ten GB of absolutely free storage for each month.)
Note that if you operate analysis on anyone else’s info and store the results in BigQuery, the new table turns into component of your storage allocation.
Observe your question charges!
The value of a question is based mostly on how a lot info the question processes and not how a lot info is returned. This is significant. If your question returns only the prime ten results just after analyzing a 4 GB info set, the question will even now use 4 GB of your info analysis quota, not just the little quantity linked to your ten rows of results.
You get one TB of info queries absolutely free each and every month each and every more TB of info processed for analysis charges $five.
If you’re running SQL queries specifically on the info, Google advises never ever running a Find * command, which goes via all out there columns. As an alternative, Find only the particular columns you have to have to slash down on the info that wants to be processed. This not only retains your charges down it also can make your queries operate quicker. I do the same with my R dplyr queries, and make certain to find only the columns I have to have.
If you’re wanting to know how you can maybe know how a lot info your question will use in advance of it runs, there’s an straightforward response. In the BigQuery cloud editor, you can style a question with out running it and then see how a lot info it will approach, as demonstrated in the screenshot down below.
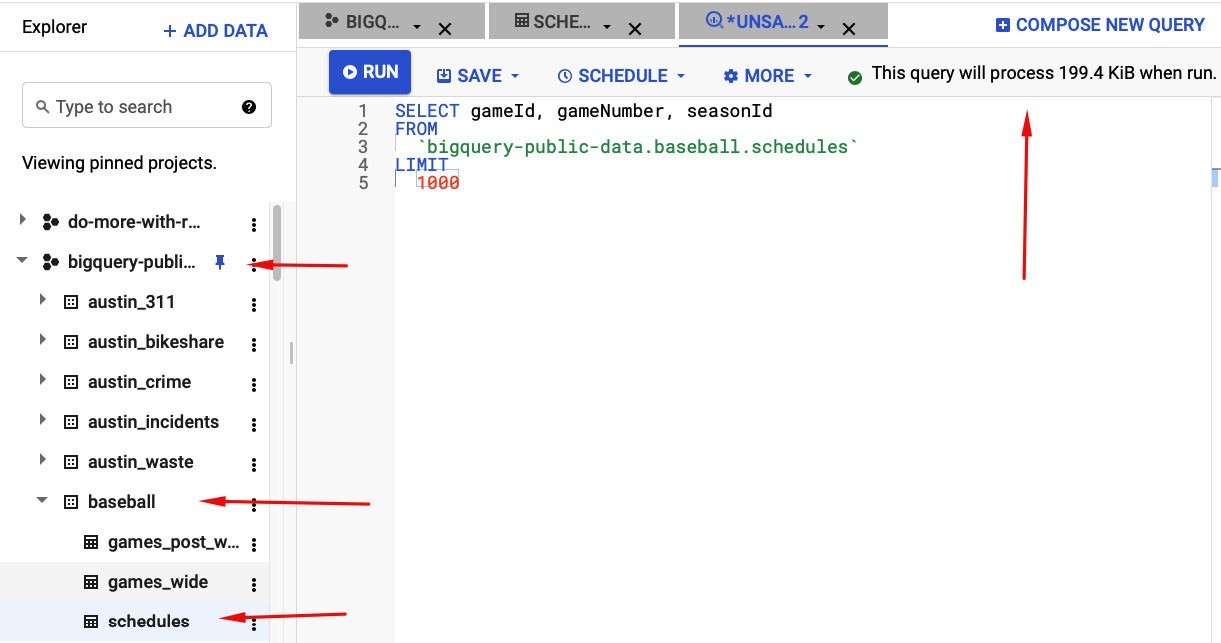 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGApplying the BigQuery SQL editor in the website interface, you can come across your table underneath its info set and venture. Typing in a question with out running it demonstrates how a lot info it will approach. Keep in mind to use `projectname.datasetname.tablename` in your question
Even if you never know SQL, you can do a simple SQL column collection to get an concept of the charge in R, due to the fact any more filtering or aggregating does not reduce the quantity of info analyzed.
So, if your question is running over three columns named columnA, columnB, and columnC in table-id, and table-id is in dataset-id which is component of venture-id, you can just style the next into the question editor:
Find columnA, columnB, columnC FROM `project-id.dataset-id.table-id`
Do not operate the question, just style it and then appear at the line at the prime correct to see how a lot info will be made use of. Whichever else your R code will be performing with that info should not issue for the question charge.
In the screenshot above, you can see that I’ve picked three columns from the schedules table, which is component of the baseball info set, which is component of the bigquery-community-info venture.
Queries on metadata are absolutely free, but you have to have to make certain you’re thoroughly structuring your question to qualify for that. For instance, applying Find Count(*) to get the quantity of rows in a info set is not billed.
There are other things you can do to limit charges. For a lot more guidelines, see Google’s “Controlling charges in BigQuery” web page.
Do I have to have to enter a credit card to use BigQuery?
No, you never have to have a credit card to start applying BigQuery. But with out billing enabled, your account is a BigQuery “sandbox” and not all queries will function. I strongly counsel incorporating a billing resource to your account even if you’re highly not likely to exceed your quota of absolutely free BigQuery analysis.
Now — at last! — let’s appear at how to tap into BigQuery with R.
Hook up to BigQuery info set in R
I’ll be applying the bigrquery bundle in this tutorial, but there are other selections you may perhaps want to contemplate, including the obdc bundle or RStudio’s skilled motorists and one particular of its organization items.
To question BigQuery info with R and bigrquery, you initially have to have to set up a link to a info set applying this syntax:
library(bigrquery)
con <- dbConnect(
bigquery(),
project = venture_id_that contains_the_info,
dataset = databases_identify
billing = your_venture_id_with_the_billing_resource
)
The initially argument is the bigquery() function from the bigrquery bundle, telling dbConnect that you want to hook up to a BigQuery info resource. The other arguments outline the venture ID, info set identify, and billing venture ID.
(Relationship objects can be named pretty a lot anything at all, but by convention they are often named con.)
The code down below hundreds the bigrquery and dplyr libraries and then creates a link to the schedules table in the baseball info set.
bigquery-community-info is the venture argument for the reason that which is where the info set lives. my_venture_id is the billing argument for the reason that my project’s quota will be “billed” for queries.
library(bigrquery)
library(dplyr)
con <- dbConnect(
bigrquery::bigquery(),
venture = "bigquery-community-info",
dataset = "baseball",
billing = "my_venture_id"
)
Almost nothing a lot transpires when I operate this code apart from producing a link variable. But the initially time I attempt to use the link, I’ll be questioned to authenticate my Google account in a browser window.
For instance, to record all out there tables in the baseball info set, I’d operate this code:
dbListTables(con)
# You will be questioned to authenticate in your browser
How to question a BigQuery table in R
To question one particular particular BigQuery table in R, use dplyr’s tbl() function to build a table object that references the table, these kinds of as this for the schedules table applying my newly developed link to the baseball info set:
skeds <- tbl(con, "schedules")
If you use the foundation R str() command to study skeds’ structure, you’ll see a record, not a info frame:
str(skeds) Record of two $ src:Record of two ..$ con :Official class 'BigQueryConnection' [bundle "bigrquery"] with seven slots .. .. ..@ venture : chr "bigquery-community-info" .. .. ..@ dataset : chr "baseball" .. .. ..@ billing : chr "do-a lot more-with-r-242314" .. .. ..@ use_legacy_sql: logi Fake .. .. ..@ web page_dimension : int 10000 .. .. ..@ silent : logi NA .. .. ..@ bigint : chr "integer" ..$ disco: NULL ..- attr(*, "class")= chr [one:4] "src_BigQueryConnection" "src_dbi" "src_sql" "src" $ ops:Record of two ..$ x : 'ident' chr "schedules" ..$ vars: chr [one:16] "gameId" "gameNumber" "seasonId" "yr" ... ..- attr(*, "class")= chr [one:3] "op_foundation_remote" "op_foundation" "op" - attr(*, "class")= chr [one:five] "tbl_BigQueryConnection" "tbl_dbi" "tbl_sql" "tbl_lazy" ...
Fortuitously, dplyr features these kinds of as glimpse() often function pretty seamlessly with this style of object (class tbl_BigQueryConnection).
Running glimpse(skeds) will return typically what you assume — apart from it does not know how quite a few rows are in the info.
glimpse(skeds)
Rows: ??
Columns: 16
Database: BigQueryConnection
$ gameId"e14b6493-9e7f-404f-840a-8a680cc364bf", "1f32b347-cbcb-4c31-a145-0e…
$ gameNumberone, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, one, 1…
$ seasonId"565de4be-dc80-4849-a7e1-54bc79156cc8", "565de4be-dc80-4849-a7e1-54…
$ yr2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2…
$ style"REG", "REG", "REG", "REG", "REG", "REG", "REG", "REG", "REG", "REG…
$ dayNight"D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D…
$ duration"3:07", "3:09", "two:forty five", "3:42", "two:44", "3:21", "two:53", "two:56", "3:…
$ duration_minutes187, 189, a hundred sixty five, 222, 164, 201, 173, 176, 180, 157, 218, 160, 178, 20…
$ homeTeamId"03556285-bdbb-4576-a06d-42f71f46ddc5", "03556285-bdbb-4576-a06d-42…
$ homeTeamName"Marlins", "Marlins", "Braves", "Braves", "Phillies", "Diamondbacks…
$ awayTeamId"55714da8-fcaf-4574-8443-59bfb511a524", "55714da8-fcaf-4574-8443-59…
$ awayTeamName"Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cu…
$ startTime2016-06-26 17:ten:00, 2016-06-twenty five twenty:ten:00, 2016-06-11 twenty:ten:00, 201…
$ attendance27318, 29457, 43114, 31625, 28650, 33258, 23450, 32358, 46206, 4470…
$ standing"closed", "closed", "closed", "closed", "closed", "closed", "closed…
$ developed2016-ten-06 06:twenty five:15, 2016-ten-06 06:twenty five:15, 2016-ten-06 06:twenty five:15, 201…
That tells me glimpse() may perhaps not be parsing via the full info set — and implies there’s a good probability it is not running up question charges but is alternatively querying metadata. When I checked my BigQuery website interface just after running that command, there certainly was no question demand.
BigQuery + dplyr analysis
You can operate dplyr commands on table objects practically the same way as you do on typical info frames. But you’ll in all probability want one particular addition: piping results from your normal dplyr workflow into the acquire() function.
The code down below makes use of dplyr to see what years and residence teams are in the skeds table object and will save the results to a tibble (special style of info frame made use of by the tidyverse suite of packages).
out there_teams <- select(skeds, homeTeamName) %>% unique() %>% acquire()
Total Billed: ten.49 MB Downloading 31 rows in one internet pages.
Pricing notice: I checked the above question applying a SQL statement trying to get the same information:
Find Distinctive `homeTeamName`
FROM `bigquery-community-info.baseball.schedules`
When I did, the BigQuery website editor confirmed that only 21.one KiB of info have been processed, not a lot more than ten MB. Why was I billed so a lot a lot more? Queries have a ten MB bare minimum (and are rounded up to the subsequent MB).
Apart: If you want to store results of an R question in a momentary BigQuery table alternatively of a area info frame, you could insert compute(identify = “my_temp_table”) to the conclude of your pipe alternatively of acquire(). Nonetheless, you’d have to have to be operating in a venture where you have permission to build tables, and Google’s community info venture is surely not that.
If you operate the same code with out acquire(), these kinds of as
out there_teams <- select(skeds, homeTeamName) %>%
unique()
you are conserving the question and not the results of the question. Note that out there_teams is now a question object with lessons tbl_sql, tbl_BigQueryConnection, tbl_dbi, and tbl_lazy (lazy indicating it won’t operate unless particularly invoked).
You can operate the saved question by applying the object identify by itself in a script:
out there_teams
See the SQL dplyr generates
You can see the SQL becoming generated by your dplyr statements with exhibit_question() at the conclude of your chained pipes:
find(skeds, homeTeamName) %>%
unique() %>%
exhibit_question()Find Distinctive `homeTeamName` FROM `schedules`
You can slash and paste this SQL into the BigQuery website interface to see how a lot info you’ll use. Just try to remember to change the simple table identify these kinds of as `schedules` to the syntax `project.dataset.tablename` in this circumstance, `bigquery-community-info.baseball.schedules`.
If you operate the same specific question a 2nd time in your R session, you won’t be billed once again for info analysis for the reason that BigQuery will use cached results.
Operate SQL on BigQuery inside of R
If you’re comfortable creating SQL queries, you can also operate SQL commands inside of R if you want to pull info from BigQuery as component of a greater R workflow.
For instance, let’s say you want to operate this SQL command:
Find Distinctive `homeTeamName` from `bigquery-community-info.baseball.schedules`
You can do so inside of R by applying the DBI package’s dbGetQuery() function. In this article is the code:
sql <- "SELECT DISTINCT homeTeamName from bigquery-public-data.baseball.schedules" library(DBI) my_results <- dbGetQuery(con, sql) Complete Billed: 10.49 MB Downloading 31 rows in 1 pages
Note that I was billed once again for the question for the reason that BigQuery does not contemplate one particular question in R and one more in SQL to be specifically the same, even if they are trying to get the same info.
If I operate that SQL question once again, I won’t be billed.
my_results2 <- dbGetQuery(con, sql) Complete Billed: 0 B Downloading 31 rows in 1 pages.
BigQuery and R
Soon after the one particular-time first setup, it is as straightforward to evaluate BigQuery info in R as it is to operate dplyr code on a area info frame. Just hold your question charges in brain. If you’re running a dozen or so queries on a ten GB info set, you won’t appear near to hitting your one TB absolutely free regular monthly quota. But if you’re operating on greater info sets everyday, it is worth hunting at ways to streamline your code.
For a lot more R guidelines and tutorials, head to my Do More With R page.
Copyright © 2021 IDG Communications, Inc.
