
Deploying information science into generation is nevertheless a massive obstacle. Not only does the deployed information science will need to be updated regularly but obtainable information resources and varieties alter promptly, as do the methods obtainable for their examination. This ongoing expansion of choices helps make it pretty limiting to depend on diligently created and agreed-on expectations or do the job entirely within just the framework of proprietary equipment.
KNIME has generally centered on offering an open platform, integrating the most current information science developments by either incorporating our have extensions or giving wrappers all-around new information resources and equipment. This allows information experts to entry and mix all obtainable information repositories and use their chosen equipment, endless by a distinct application supplier’s choices. When using KNIME workflows for generation, entry to the exact information resources and algorithms has generally been obtainable, of program. Just like lots of other equipment, nevertheless, transitioning from information science creation to information science generation associated some intermediate methods.
In this write-up, we are describing a modern addition to the KNIME workflow motor that allows the pieces required for generation to be captured immediately within just the information science creation workflow, producing deployment completely automatic although nevertheless allowing for every single module to be applied that is obtainable throughout information science creation.
Why is deploying information science in generation so tough?
At first glance, putting information science in generation seems trivial: Just run it on the generation server or picked device! But on nearer examination, it will become clear that what was constructed throughout information science creation is not what is currently being put into generation.
I like to examine this to the chef of a Michelin star cafe who patterns recipes in his experimental kitchen area. The route to the perfect recipe includes experimenting with new ingredients and optimizing parameters: portions, cooking situations, etc. Only when contented, are the closing results — the record of ingredients, portions, treatment to prepare the dish — put into producing as a recipe. This recipe is what is moved “into generation,” i.e., manufactured obtainable to the tens of millions of cooks at home that purchased the ebook.
This is pretty similar to coming up with a option to a information science problem. For the duration of information science creation, distinctive information resources are investigated that information is blended, aggregated, and transformed then many types (or even combinations of types) with lots of probable parameter options are tried out out and optimized. What we put into generation is not all of that experimentation and parameter/design optimization — but the mix of picked information transformations together with the closing finest (set of) realized types.
This nevertheless sounds straightforward, but this is wherever the gap is generally largest. Most equipment let only a subset of probable types to be exported lots of even overlook the preprocessing totally. All much too often what is exported is not even all set to use but is only a design representation or a library that requirements to be eaten or wrapped into still another resource before it can be put into generation. As a outcome, the information experts or design operations staff requirements to incorporate the selected information mixing and transformations manually, bundle this with the design library, and wrap all of that into another application so it can be put into generation as a all set-to-eat services or application. Plenty of particulars get dropped in translation.
For our Michelin chef earlier mentioned, this manual translation is not a substantial problem. She only produces or updates recipes every single other calendar year and can spend a day translating the results of her experimentation into a recipe that is effective in a normal kitchen area at home. For our information science staff, this is a a great deal larger problem: They want to be ready to update types, deploy new equipment, and use new information resources whenever required, which could simply be on a everyday or even hourly basis. Including manual methods in in between not only slows this approach to a crawl but also adds lots of further resources of error.
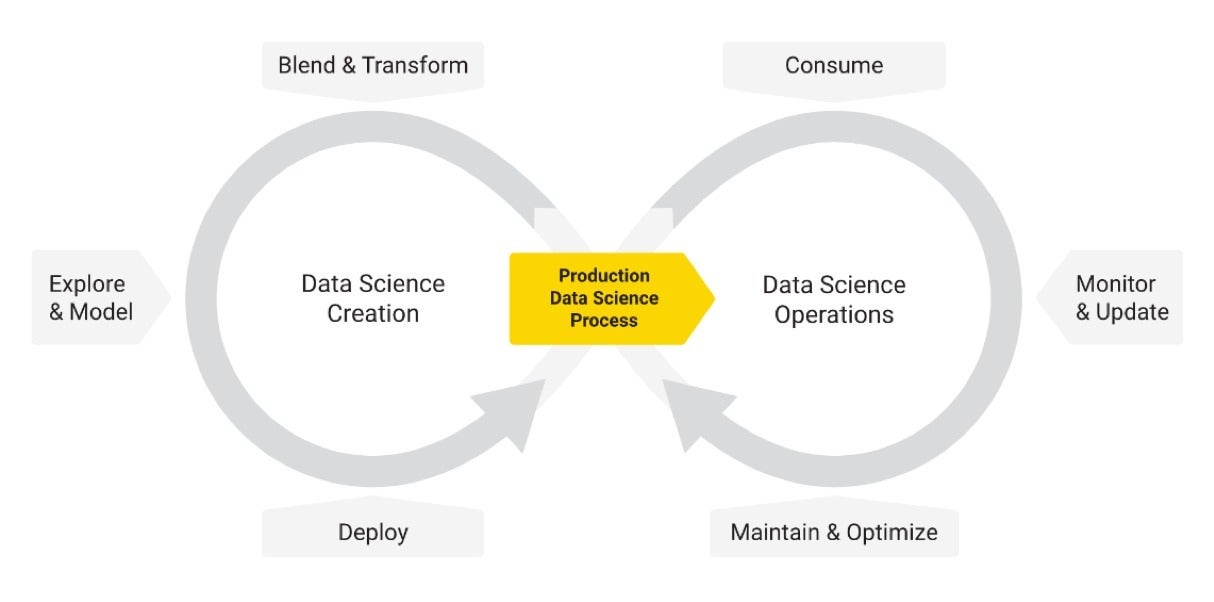
The diagram under shows how information science creation and productionization intertwine. This is motivated by the classic CRISP-DM cycle but puts more powerful emphasis on the ongoing nature of information science deployment and the prerequisite for frequent checking, automatic updating, and comments from the organization facet for ongoing advancements and optimizations. It also distinguishes much more obviously in between the two distinctive activities: creating information science and putting the ensuing information science approach into generation.
 KNIME
KNIMEGenerally, when men and women discuss about “end-to-close information science,” they really only refer to the cycle on the remaining: an built-in technique covering almost everything from information ingestion, reworking, and modeling to producing out some kind of a design (with the caveats explained earlier mentioned). Truly consuming the design already requires other environments, and when it arrives to continued checking and updating of the design, the resource landscape will become even much more fragmented. Routine maintenance and optimization are, in lots of conditions, pretty rare and greatly manual duties as nicely. On a facet notice: We prevent the time period “model ops” purposely right here simply because the information science generation approach (the aspect which is moved into “operations”) is composed of a great deal much more than just a design.
Eliminating the gap in between information science creation and information science generation
Built-in deployment removes the gap in between information science creation and information science generation by enabling the information scientist to design equally creation as nicely as generation within just the exact setting by capturing the pieces of the approach that are required for deployment. As a outcome, whenever adjustments are manufactured in information science creation, these adjustments are instantly reflected in the deployed extract as nicely. This is conceptually straightforward but shockingly challenging in truth.
If the information science setting is a programming or scripting language, then you have to be painfully thorough about creating appropriate subroutines for every single aspect of the overall approach that could be valuable for deployment — also producing certain that the necessary parameters are properly passed in between the two code bases. In impact, you have to create two applications at the exact time, ensuring that all dependencies in between the two are generally observed. It is straightforward to pass up a little piece of information transformation or a parameter that is required to properly use the design.
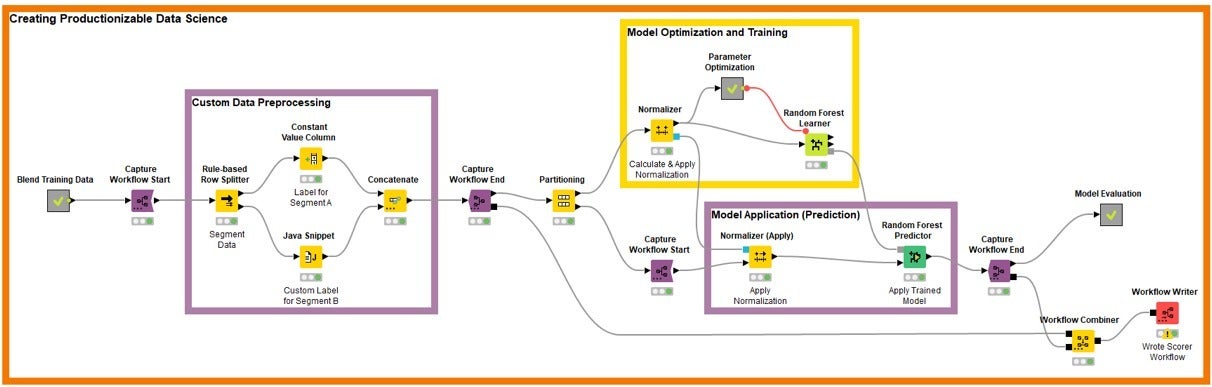
Making use of a visible information science setting can make this much more intuitive. The new Built-in Deployment node extensions from KNIME let those people parts of the workflow that will also be required in deployment to be framed or captured. The motive this is so straightforward is that those people parts are normally a aspect of the creation workflow. This is simply because first, the precise exact transformation parts are required throughout design training, and 2nd, analysis of the types is required throughout fantastic tuning. The adhering to impression shows a pretty straightforward illustration of what this looks like in observe:
 KNIME
KNIMEThe purple packing containers seize the pieces of the information science creation approach that are also required for deployment. Alternatively of having to copy them or having to go by an express “export model” action, now we simply just incorporate Seize-Get started/Seize-Close nodes to frame the pertinent parts and use the Workflow-Combiner to put the parts together. The ensuing, instantly created workflow is demonstrated under:
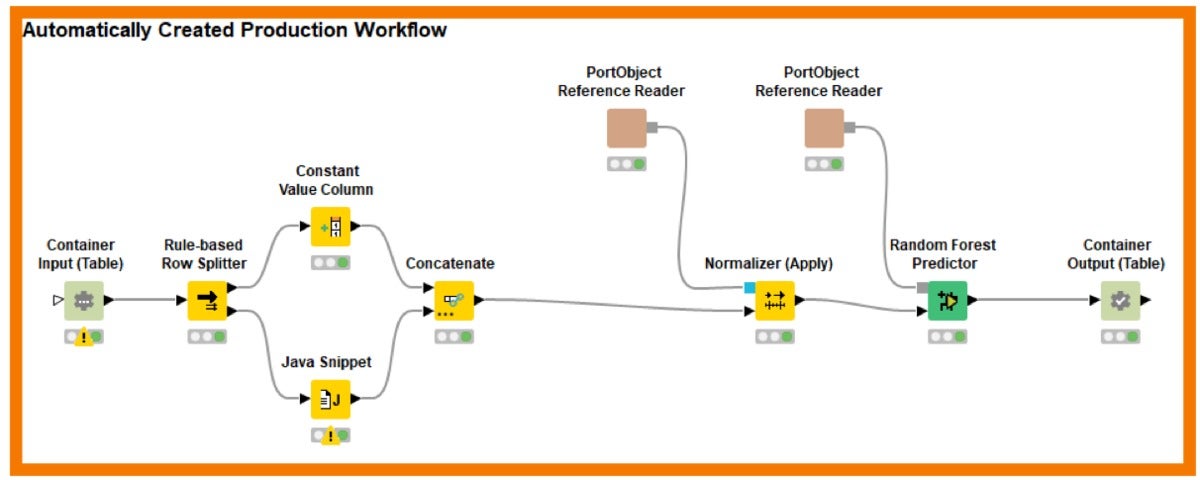 KNIME
KNIMEThe Workflow-Author nodes occur in distinctive designs that are valuable for all probable means of deployment. They do just what their identify implies: create out the workflow for somebody else to use as a starting off position. But much more highly effective is the capacity to use Workflow-Deploy nodes that instantly add the ensuing workflow as a Rest services or as an analytical application to KNIME Server or deploy it as a container — all probable by using the suitable Workflow-Deploy node.
The intent of this article is not to describe the complex elements in fantastic element. Nonetheless, it is important to position out that this seize and deploy system is effective for all nodes in KNIME — nodes that supply entry to native information transformation and modeling tactics as nicely as nodes that wrap other libraries this kind of as TensorFlow, R, Python, Weka, Spark, and all of the other third-social gathering extensions delivered by KNIME, the group, or the companion community.
With the new Built-in Deployment extensions, KNIME workflows convert into a comprehensive information science creation and productionization setting. Facts experts constructing workflows to experiment with constructed-in or wrapped tactics can seize the workflow for immediate deployment within just that exact workflow. For the first time, this permits instantaneous deployment of the comprehensive information science approach immediately from the setting applied to build that approach.
Michael Berthold is CEO and co-founder at KNIME, an open supply information analytics firm. He has much more than 25 yrs of working experience in information science, functioning in academia, most recently as a total professor at Konstanz University (Germany) and beforehand at University of California (Berkeley) and Carnegie Mellon, and in market at Intel’s Neural Community Team, Utopy, and Tripos. Michael has printed extensively on information analytics, machine discovering, and artificial intelligence. Follow Michael on Twitter, LinkedIn and the KNIME web site.
—
New Tech Discussion board delivers a location to explore and examine rising business engineering in unparalleled depth and breadth. The assortment is subjective, dependent on our choose of the systems we believe to be important and of greatest interest to InfoWorld audience. InfoWorld does not take advertising and marketing collateral for publication and reserves the ideal to edit all contributed content material. Deliver all inquiries to [email protected].
Copyright © 2020 IDG Communications, Inc.
