
Convolutional neural networks (CNNs) have enabled many AI-enhanced programs, these kinds of as impression recognition. Even so, the implementation of point out-of-the-art CNNs on reduced-energy edge equipment of Web-of-Factors (IoT) networks is challenging due to the fact of big resource needs. Researchers from Tokyo Institute of Engineering have now solved this challenge with their successful sparse CNN processor architecture and education algorithms that enable seamless integration of CNN styles on edge equipment.
With the proliferation of computing and storage equipment, we are now in an details-centric era in which computing is ubiquitous, with computation products and services migrating from the cloud to the “edge,” letting algorithms to be processed domestically on the product. These architectures enable a variety of smart internet-of-issues (IoT) programs that conduct complex responsibilities, these kinds of as impression recognition.
Convolutional neural networks (CNNs) have firmly established them selves as the regular technique for impression recognition complications. The most precise CNNs normally include hundreds of levels and 1000’s of channels, resulting in improved computation time and memory use. Even so, “sparse” CNNs, obtained by “pruning” (removing weights that do not signify a model’s performance), have noticeably lessened computation expenditures whilst retaining product accuracy. This sort of networks final result in a lot more compact variations that are appropriate with edge equipment. The advantages, even so, arrive at a charge: sparse procedures limit bodyweight reusability and final result in irregular info structures, building them inefficient for serious-world options.
Addressing this concern, Prof. Masato Motomura and Prof. Kota Ando from Tokyo Institute of Engineering (Tokyo Tech), Japan, alongside with their colleagues, have now proposed a novel 40 nm sparse CNN chip that achieves each substantial accuracy and performance, working with a Cartesian-product or service MAC (multiply and accumulate) array (Figures one and two), and “pipelined activation aligners” that spatially shift “activations” (the established of enter/output values or, equivalently, the enter/output vector of a layer) on to regular Cartesian MAC array.
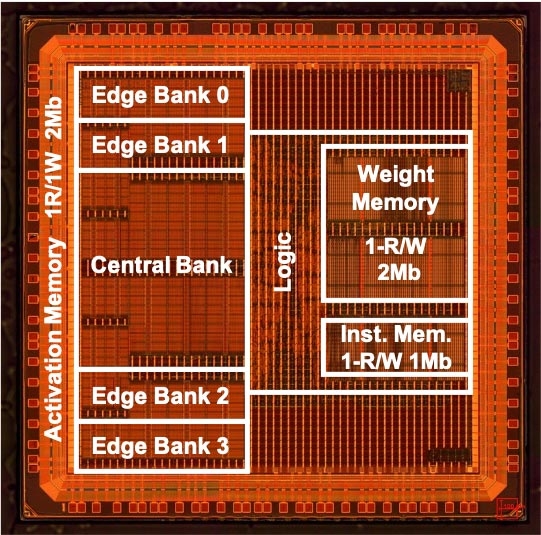
Figure one. The prototype chip fabricated in 40 nm technological innovation
Researchers from Tokyo Tech proposed a novel CNN architecture working with Cartesian product or service MAC (multiply and accumulate) array in the convolutional layer.
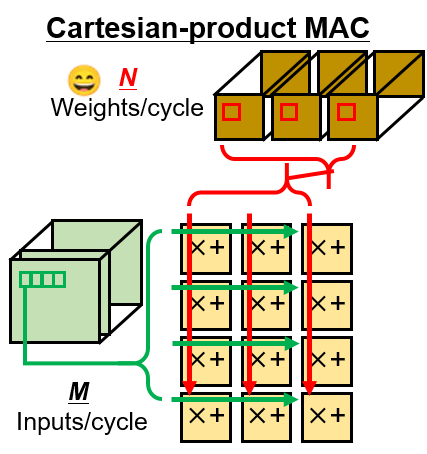
Figure two. The Cartesian product or service MAC array for maximizing arithmetic depth of pointwise convolution
“Regular and dense computations on a parallel computational array are a lot more successful than irregular or sparse types. With our novel architecture utilizing MAC array and activation aligners, we were being able to realize dense computing of sparse convolution,” states Prof. Ando, the principal researcher, conveying the importance of the study. He adds, “Moreover, zero weights could be eradicated from each storage and computation, resulting in improved resource utilization.” The results will be introduced at the thirty third Yearly Very hot Chips Symposium.
1 important component of the proposed mechanism is its “tunable sparsity.” Whilst sparsity can minimize computing complexity and therefore boost performance, the amount of sparsity has an impact on prediction accuracy. Therefore, modifying the sparsity to the ideal accuracy and performance can help unravel the accuracy-sparsity connection. In order to acquire extremely successful “sparse and quantized” styles, scientists used “gradual pruning” and “dynamic quantization” (DQ) techniques on CNN styles qualified on regular impression datasets, these kinds of as CIFAR100 and ImageNet. Gradual pruning associated pruning in incremental methods by dropping the smallest bodyweight in every channel (Figure 3), whilst DQ served quantize the weights of neural networks to reduced bit-length quantities, with the activations currently being quantized all through inference. On screening the pruned and quantized product on a prototype CNN chip, scientists measured five.thirty dense TOPS/W (tera operations for every 2nd for every watt—a metric for evaluating performance performance), which is equal to 26.five sparse TOPS/W of the foundation product.

The qualified product was pruned by removing the cheapest bodyweight in every channel. Only a single factor continues to be following eight rounds of pruning (pruned to one/9). Each of the pruned styles is then subjected to dynamic quantization.
“The proposed architecture and its successful sparse CNN education algorithm enable sophisticated CNN styles to be integrated into reduced-energy edge equipment. With a selection of programs, from smartphones to industrial IoTs, our study could pave the way for a paradigm shift in edge AI,” remarks an fired up Prof. Motomura.
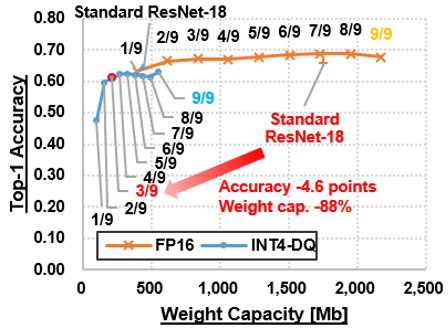
Figure 3. Working with gradual pruning and dynamic quantization to manage the accuracy-performance trade-off
It surely looks that the upcoming of computing lies on the “edge” !
Source: Tokyo Institute of Engineering
